April 13, 2026

Every enterprise has a version of this story. A leadership question that should take minutes takes days. Not because the data doesn't exist, but because it lives in six different systems that were never designed to talk to each other. The analyst who finally delivers the answer had to discover the right sources, assemble them manually, reconcile conflicting definitions, and then hope the result is correct. The tools they used along the way were no help with any of that.
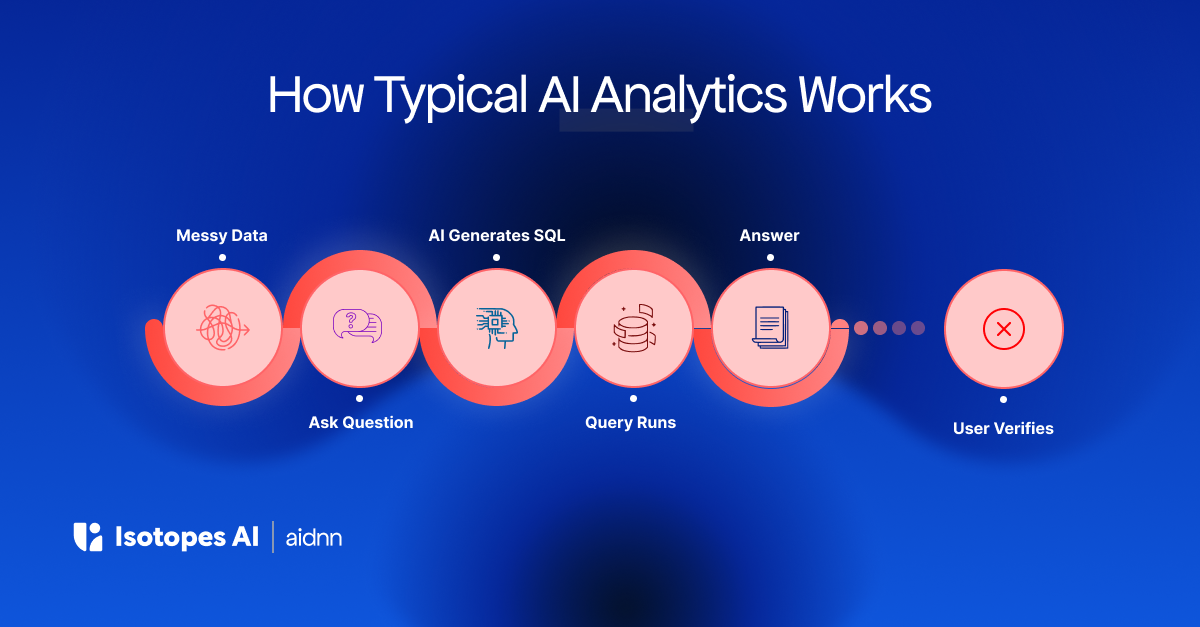
This is the environment most AI analytics tools pretend doesn't exist.
Enterprise data isn't messy because data teams are failing. It's messy because of how modern businesses actually operate.
Every SaaS tool a company adopts creates a new data silo with its own schema and its own definition of core entities. Every acquisition brings a different system, often a different stack entirely. Every integration partner sends data in their own format. Every operational system, the ones that actually run the business, produces data that never fully lands in the warehouse because it was never designed to.
The modern data stack was supposed to centralize all of this. And the individual tools are good at what they do. dbt models what's in the warehouse. Alation catalogs what's been modeled. Fivetran moves data from A to B. But each one solves one piece and adds another integration boundary. None of them reconcile conflicting definitions across systems. None of them assemble a complete picture from sources that were never designed to connect.
The number of sources per enterprise is growing, not shrinking. The warehouse is the biggest source, not the single source of truth. This isn't a phase. It's permanent.
The obvious cost of fragmented data is inaccurate reports. The real cost is much larger: it's the decisions that never get made.
The cross-system analysis that would surface a major inefficiency, but nobody runs it because assembling the data would take two weeks and three teams. The reconciliation between two sources that would settle a debate, but nobody trusts either number enough to start. The question from a board member that gets a hedged, "directionally correct" answer because the real answer requires joining systems that have never been connected.
Then there's the labor tax. Analysts spending 80% of their time on data assembly and reconciliation, not analysis. Data engineers fielding ad hoc requests to build one-off joins. Teams waiting days for answers to questions that should take minutes.
This is the work that chat-with-data tools skip entirely. They generate SQL against a single well-modeled warehouse and assume someone else handled the hard part. Nobody did.
The default response is to clean the data first. Standardize schemas. Build golden records. Run a data quality initiative. Then deploy analytics.
This sounds reasonable. It also never ends. New SaaS tools get adopted. Acquisitions close. Partner integrations evolve. Business rules shift. The cleanup project you finished last quarter is already out of date.
More importantly, it puts the burden on the wrong people. Business users who need answers are told to wait. Data engineers already stretched thin get another multi-quarter project. And the analytics tools that were supposed to accelerate everything sit idle until preconditions are met.
The preconditions are never fully met.
What messy data actually looks like:
Inconsistent schemas. Your CRM defines a customer one way. Your warehouse defines it another. Your billing system uses a third definition.
Duplicate records. The same transaction or event appears more than once, silently inflating totals and skewing averages.
Bad joins. Two tables connect on a field that should match but doesn't, because naming conventions changed or a migration introduced errors.
Missing business logic. Fiscal calendars, metric definitions, org hierarchies, product taxonomies: the logic that makes data meaningful lives in spreadsheets, email threads, or someone's head.
Fragmented sources. The data needed to answer the question lives across your warehouse, SaaS tools, ERP, partner feeds, operational systems, and a handful of spreadsheets someone emailed last quarter.
The path forward isn't to pretend fragmentation doesn't exist. It's to build analytics that are designed for it.
A system that connects to data where it lives, across warehouses, databases, SaaS platforms, operational systems, and files, without requiring everything to be pre-loaded into a single warehouse. A system that understands the semantic meaning of your data, not just the schema, and reconciles conflicting definitions instead of silently picking one. A system that learns your business context over time and verifies its outputs before you ever see them.

That is what aidnn was built for. Not to query clean data. To find answers in the gaps between systems, with the data you actually have.