April 13, 2026

Every AI analytics tool on the market will tell you it's accurate. None of them can show you the proof.
That distinction, between claiming accuracy and proving it, is the difference between analytics you present in a board meeting and analytics you quietly double-check before you do.
Most tools work the same way: a user asks a question, the tool generates code, the query runs, and an answer surfaces. At no point does the system check its own work. Whether the answer is correct is your problem.
When an analytics tool fails obviously, it's fine. An error message, a timeout, a query that won't compile. You know something broke. You fix it or you escalate.
The dangerous failure is different. It's a clean chart with a confident number that happens to be wrong. Code that executed perfectly but pulled from the wrong source. A join that silently inflated row counts. An aggregation that dropped a category because of a schema mismatch nobody noticed. A year-over-year comparison where the two years use different fiscal calendar definitions.
These errors don't announce themselves. They surface as finished analyses that look right, get presented to leadership, and drive decisions. The analyst reviewing the output has no way to distinguish a correct result from a plausible one without manually retracing every step. Which is exactly the work the tool was supposed to eliminate.
This is where the entire "chat with your data" category breaks down. Not on the easy questions against a single clean table. On the hard ones, the cross-system analyses where the answer requires assembly, reconciliation, and multi-step reasoning. The questions that matter most are the ones most likely to produce confident wrong answers.
The obvious response is to add a verification step. Ask the model to review its own output. Run the query twice. Add a confidence score.
None of this works.
Asking a model to check its own work is like asking the person who wrote a report to proofread it. They'll miss the same errors they made the first time, because they're operating with the same assumptions, the same blind spots, and the same context. Running the same model twice produces the same class of errors. A confidence score tells you how confident the model is, not whether the answer is correct. These are fundamentally different things.
Verification requires independence. The agent checking the work must have different incentives, different reasoning, and ideally a different model architecture than the agent that produced the work. This is why single-model AI systems hit an accuracy ceiling of around 55% on complex analytics tasks. Not because the models are bad, but because they are not designed to catch their own errors. Otherwise you're not verifying. You're rubber-stamping.

Verified analytics is a specific standard, not a marketing phrase.
It means every step in an analytical pipeline is independently validated as it executes. Not after the fact. During execution. If a data assembly step produces unexpected nulls, if a join inflates row counts, if an aggregation silently drops categories, these errors are caught and corrected before they propagate downstream into the final result.
It means the completed analysis is examined by independent reasoning agents that generate mathematical constraints: invariants that must hold if the answer is correct. Revenue by region must sum to total revenue. Growth rates applied to the starting value must reproduce the ending value. A cross-source reconciliation must be bidirectionally consistent. These constraints are then tested computationally. Not eyeballed. Not estimated. Tested.
It means the agents doing the verification have opposing incentives to the agents that produced the work. This is the difference between a newsroom where the reporter also does fact-checking, and one where an independent fact-checker's job is to find problems. aidnn's architecture is built on this principle: agents that are structurally motivated to challenge each other's work. A team of rivals, not a team of yes-men.
And it means full evidence on every answer. The framework is simple: Trust = Transparency + Repeatability + Verification. Transparency means the full reasoning chain is visible: the plan, the code, the execution, the verification. No black boxes. Repeatability means the same question asked twice returns the same answer, consistency by design, not luck. Verification means the system proves its output before you see it. Most tools offer partial transparency at best. None offer all three.
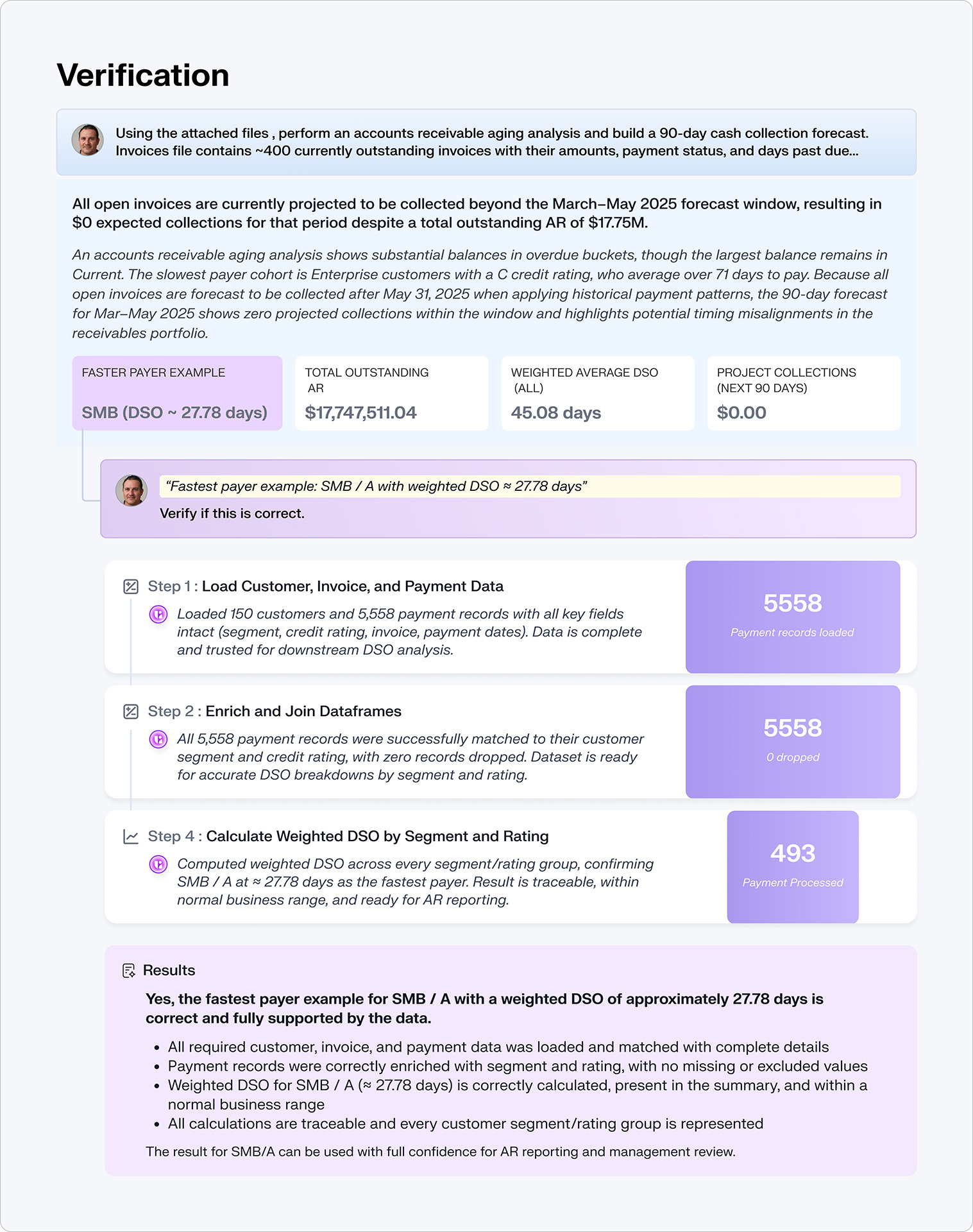
aidnn's verification architecture has two layers because there are two fundamentally different classes of error.
Step verification catches execution errors. The code did something wrong: a bad join, a misapplied filter, a type mismatch that produced silent nulls. As published in the aidnn Team of Rivals" paper (arXiv, January 2026), independent agents running different models verify every step in the pipeline as it runs. Not the same model reviewing its own output. Different models, with different strengths and different failure modes, checking each other's work in real time. Errors are caught before they compound into the final result. This was validated across 522 production sessions at a 92.1% end-to-end success rate. Real production workloads with real customer data, not benchmarks.
Deep verification catches a fundamentally different and more dangerous class of error: reasoning errors. The code ran correctly, but the analytical approach was flawed. The wrong metric was computed. The wrong comparison was made. The result is internally inconsistent in ways that only surface when you test mathematical properties of the output. This layer uses separate, more powerful reasoning models that examine the completed analysis, generate mathematical constraints (invariants that must hold if the answer is correct), and test each one computationally. Deep verification runs on demand for high-stakes analyses, creating a natural quality tier: routine questions get step verification automatically, critical analyses get the full adversarial treatment.
The two layers are complementary because they use different models optimized for different tasks. Step verification agents are optimized for code review and execution correctness. Deep verification agents are optimized for mathematical reasoning and logical consistency. No single model can reliably catch both classes of error. By coordinating agents across model architectures with opposing incentives, aidnn scales reliability from 50-60% per individual model to over 90% for the system.
Verification is expensive. It requires running additional agents, additional computation, additional reasoning on every analysis. It requires an architecture designed from the ground up around adversarial validation, not a chatbot with a review step bolted on.
Platform vendors like Snowflake and Databricks are building increasingly capable native analytics agents. But their incentive is compute consumption inside their platform. A verification architecture that catches errors before they reach the user means fewer wasted queries, fewer re-runs, fewer cycles of "that doesn't look right, try again." It's aligned with the customer's interest but not naturally aligned with a platform whose revenue scales with usage.
Chat-with-data startups could theoretically add verification. But it requires a fundamentally different architecture: multi-agent, multi-model, with explicit separation of reasoning and execution and structurally opposed incentives. You can't bolt that onto a single-model text-to-SQL pipeline. You have to build it from scratch.
This is why aidnn is the only platform with this architecture in production. Not because the idea is secret. Because the engineering is hard and the incentives for incumbents point elsewhere.
The next time you evaluate an AI analytics tool, ask one question: can you show me the proof?
Not "is this accurate?" Every vendor will say yes. Not "how confident are you?" Confidence is not correctness. Ask to see the verification. The reasoning chain. The mathematical checks. The evidence that the answer was proven, not just produced.
If the answer is "the user catches errors," you are the verification layer. You are doing the work the tool was supposed to do. And on the hardest, highest-stakes analyses, the ones where being wrong is most expensive, you are least likely to catch it.
Verified analytics is the standard the market should demand. Not a feature upgrade to existing tools. A different standard entirely.